2D 이미지에서 3D 공간이 만들어지는 과정
디지털 트윈을 처음 공부하면 가장 먼저 이런 생각이 듭니다.
“현실을 디지털로 그대로 옮긴다는데, 그걸 어떻게 만드는 걸까?”
겉으로 보면 디지털 트윈은 그냥 멋진 3D 화면처럼 보일 수 있습니다.
하지만 실제로는 단순히 예쁜 그래픽을 만드는 일이 아닙니다.
핵심은 현실 세계를 컴퓨터가 이해할 수 있는 3차원 정보로 바꾸는 것입니다.
그리고 그 출발점이 바로 3D 재구성(3D Reconstruction) 입니다.
이번 글에서는 3D 분야를 처음 접하는 분도 이해할 수 있도록,
2D 이미지가 어떻게 3D 공간 표현으로 이어지는지를 아주 기초부터 천천히 설명해보겠습니다.
1. 왜 3D 재구성이 필요할까?
우리가 스마트폰이나 카메라로 찍는 사진은 기본적으로 2D 이미지입니다.
가로와 세로 정보는 있지만, 실제로 얼마나 떨어져 있는지, 어떤 구조를 갖는지 같은 깊이 정보는 바로 드러나지 않습니다.
그런데 디지털 트윈은 단순 사진 저장이 목적이 아닙니다.
현실의 건물, 설비, 물체, 공간을 거리와 구조를 가진 3D 상태로 다뤄야 합니다.
그래야 다른 시점에서 다시 볼 수 있고, 충돌을 확인할 수 있고, 공간 안에서 움직임을 시뮬레이션할 수도 있습니다.
다시 말해,
디지털 트윈은 “사진 모음”이 아니라
현실 공간을 디지털 공간으로 옮긴 모델이어야 합니다.

2. 3D 재구성은 어떤 과정을 거칠까?
전통적인 3D 재구성 흐름은 보통 다음과 같습니다.
Image Acquisition → Depth Map Reconstruction → Camera Pose Estimation → Dense Correspondences → 3D Geometry Reconstruction → Textured 3D Reconstruction입니다.
처음 보면 용어가 꽤 많아 보입니다.
그런데 사실 하나씩 풀어보면,
“사진을 모으고 → 거리와 위치를 추정하고 → 형태를 복원하고 → 겉모습을 입힌다”는 흐름입니다.
여기서 중요한 건,
3D 재구성은 한 번에 뚝딱 만들어지는 마법 같은 과정이 아니라,
여러 단계를 거쳐 점진적으로 공간 정보를 복원하는 과정이라는 점입니다.
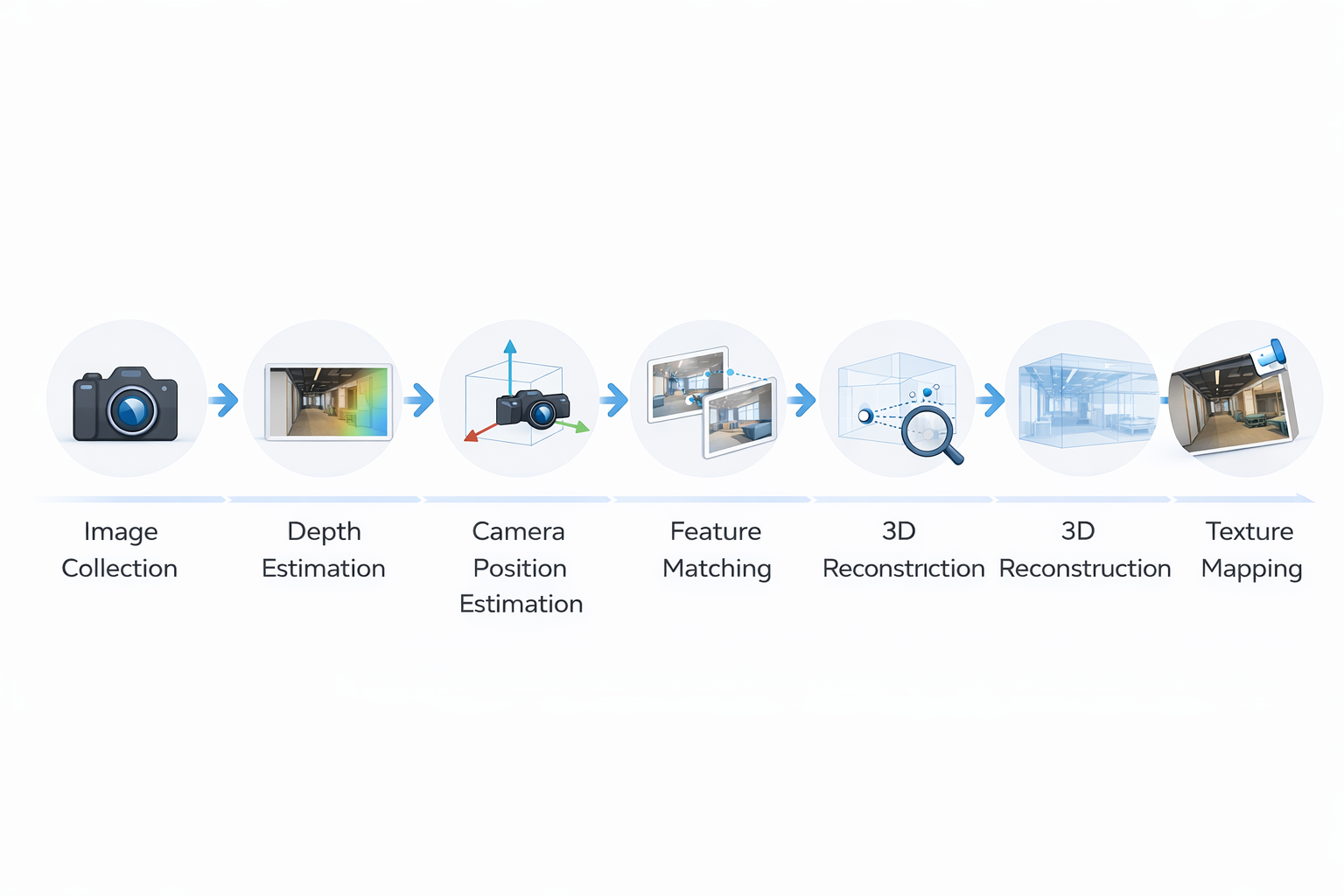
3. 단계별로 정말 쉽게 이해해보자
3-1. Image Acquisition
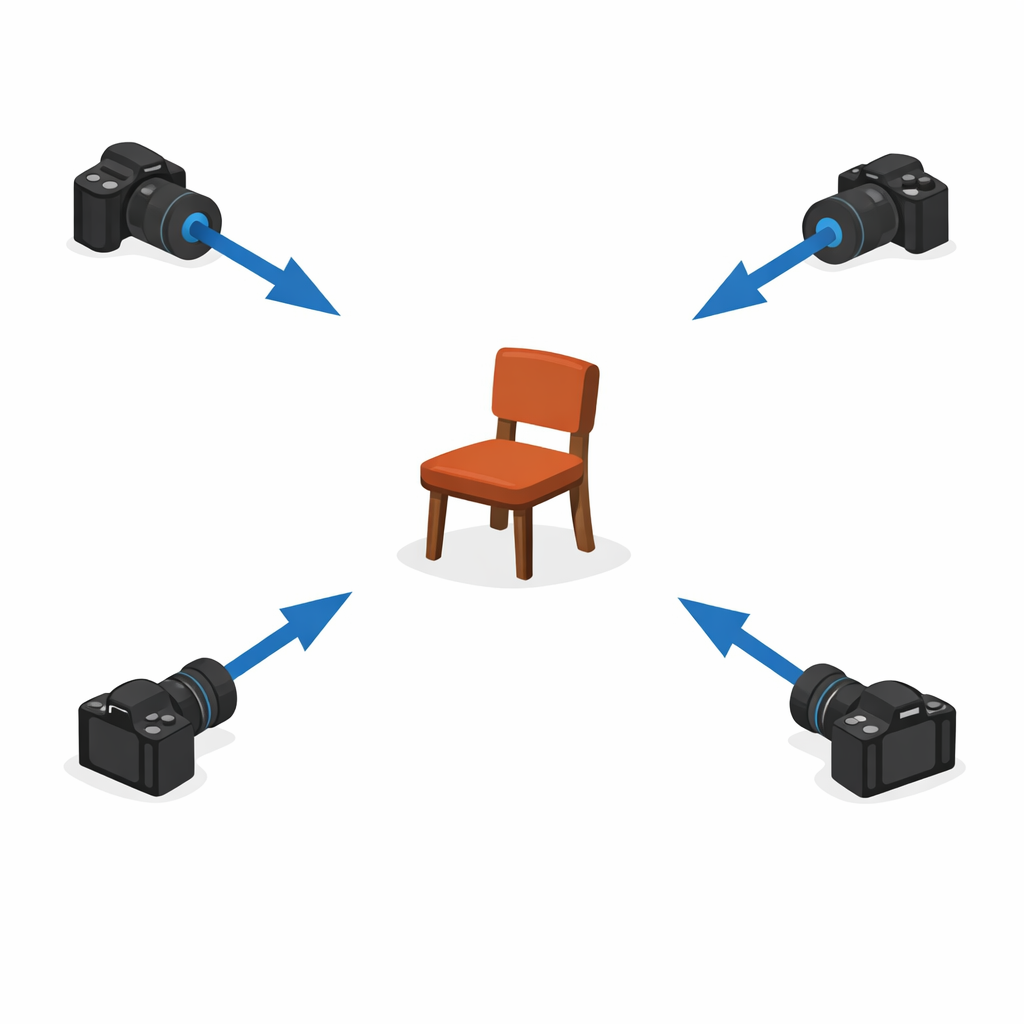
가장 먼저 해야 할 일은 이미지를 모으는 것입니다.
한 장만 쓸 수도 있지만, 보통은 여러 각도에서 찍은 여러 장의 이미지가 더 유리합니다.
예를 들어 건물을 디지털 공간에 옮기고 싶다면,
입구 쪽에서 한 장, 측면에서 한 장, 위쪽에서 한 장처럼
다양한 시점의 정보가 필요합니다.
왜냐하면 사진 한 장만으로는 가려진 면이나 깊이를 완전히 알기 어렵기 때문입니다.
쉽게 말해 이 단계는
현실 세계에서 디지털 트윈의 재료를 수집하는 단계입니다.
3-2. Depth Map Reconstruction
다음은 깊이(depth) 를 추정하는 단계입니다.
사진은 평면이라서,
어떤 픽셀이 가까운 물체인지, 어떤 픽셀이 먼 배경인지 바로 알기 어렵습니다.
그래서 픽셀마다 “카메라로부터 얼마나 떨어져 있는가”를 추정해서 깊이 맵(depth map) 을 만듭니다.
깊이 맵을 처음 보는 분은 이렇게 생각하면 됩니다.
- 밝을수록 가깝다
- 어두울수록 멀다
혹은 그 반대의 색 규칙을 정해서,
각 픽셀의 거리를 표현한 지도라고 보면 됩니다.
즉 RGB 이미지는 색 정보를 담고,
Depth map은 거리 정보를 담습니다.
이 둘이 합쳐져야 비로소 입체적인 이해가 가능해집니다.

3-3. Camera Pose Estimation

이 단계는 말이 조금 어렵지만, 핵심은 단순합니다.
“이 사진이 어디서, 어떤 방향으로 찍혔는가?”를 추정하는 것입니다.
여러 장의 사진이 있을 때,
컴퓨터는 각 사진이 공간 안에서 어떤 위치 관계를 가지는지 알아야 합니다.
그래야 서로 다른 이미지들을 하나의 3D 공간 안에 맞춰 넣을 수 있습니다.
예를 들어 같은 책상을
정면, 왼쪽, 오른쪽에서 찍었다면,
각 사진의 카메라 위치를 알아야
“아 이건 같은 책상을 다른 각도에서 본 거구나” 하고 정렬할 수 있습니다.
이 단계가 없으면
이미지는 많아도 서로의 관계를 모르기 때문에
3D 공간으로 묶어내기가 어렵습니다.
3-4. Dense Correspondences

이건 두 이미지 이상에서 같은 실제 지점을 서로 대응시키는 과정입니다.
예를 들어 첫 번째 사진의 창문 모서리와
두 번째 사진의 창문 모서리가
사실은 같은 실제 위치라는 것을 알아야 합니다.
사람은 직관적으로 “이건 같은 창문이네”라고 알 수 있지만,
컴퓨터는 픽셀 수준에서 그 대응 관계를 찾아야 합니다.
이 대응점이 많아질수록
공간 구조를 더 안정적으로 복원할 수 있습니다.
처음 공부할 때는
이 단계를 “사진들 사이의 공통 지점을 찾는 과정” 정도로 이해하면 충분합니다.
3-5. 3D Geometry Reconstruction
이제 앞에서 모은 정보들을 바탕으로
드디어 3차원 형태 자체를 복원합니다.
여기서부터는 단순히 사진을 보는 것이 아니라,
벽이 어디 있고, 표면이 어디로 이어지고,
물체의 구조가 어떤지를 3D 형태로 만들기 시작합니다.
이 단계의 핵심은
“사진들의 관계를 이용해서 공간 구조를 만들어낸다”는 점입니다.
쉽게 말해,
앞 단계까지가 재료 준비였다면
이 단계는 본격적으로 3D 형태를 세우는 단계입니다.
3-6. Textured 3D Reconstruction

하지만 형태만 복원하면 아직 조금 부족합니다.
색감과 표면 느낌이 없으면 회색 조형물처럼 보일 수 있기 때문입니다.
그래서 마지막에는 복원된 3D 구조 위에
원래 이미지의 색과 질감을 입혀
더 현실적인 결과로 만듭니다.
즉,
- Geometry = 형태
- Texture = 겉모습
이라고 이해하면 쉽습니다.
4. 결국 3D 재구성의 본질은 무엇일까?
강의자료에서는 3D 재구성의 목표를 아주 간단하게 정리합니다.
입력은 2D RGB 이미지이고, 출력은 3D representation입니다.
이 한 줄이 사실 오늘 글의 핵심입니다.
즉 3D 재구성은
“사진을 예쁘게 바꾸는 기술”이 아니라,
2D 이미지에서 3D 공간 표현을 만드는 기술입니다.
그리고 디지털 트윈은 바로 그 3D 공간 표현 위에서 시작됩니다.
공간이 제대로 디지털화되어 있어야
나중에 센서를 붙이고, 움직임을 분석하고,
시뮬레이션도 할 수 있기 때문입니다.
5. 그런데 3D는 어떤 방식으로 표현할까?
여기서 자연스럽게 다음 질문이 나옵니다.
“좋아, 3D로 바꾼다는 건 알겠는데,
그 3D는 컴퓨터 안에서 어떤 형식으로 저장되는 걸까?”
강의자료에서는 3D 표현을 크게
voxel, point, mesh 같은 명시적 표현과
implicit representation 같은 암묵적 표현으로 나눕니다.
초보자 입장에서는 여기서부터 조금 헷갈릴 수 있습니다.
그래서 오늘은 아주 감각적으로만 잡아보겠습니다.
- Voxel: 3D 픽셀처럼 공간을 작은 큐브로 나눈 방식
- Point Cloud: 3D 공간 속 점들을 많이 모아놓은 방식
- Mesh: 점들을 이어 삼각형 표면으로 만든 방식
- Implicit: 표면을 직접 저장하지 않고, 함수로 공간을 정의하는 방식
이 네 가지는 다음 글에서 본격적으로 비교해볼 예정이지만,
이번 글에서는 “3D를 표현하는 방식도 여러 종류가 있다”는 감각만 잡으면 충분합니다.

6. 왜 최근에는 Implicit 표현과 NeRF가 주목받을까?
최근 3D 분야에서
implicit function 기반의 neural volumetric representation이
이미지로부터 3D 객체와 장면을 표현하고,
새로운 시점의 사실적인 이미지를 렌더링하는 강력한 방식으로 떠올랐다고 합니다.
또 한편으로는 기존 방식들이
정확한 3D ground truth가 필요하거나,
격자화 과정에서 해상도와 계산량 한계를 겪는다고도 합니다.
이 말이 조금 어렵게 느껴질 수 있는데,
쉽게 말하면 이렇습니다.
예전 방식은 3D를 다루는 방법이 다소 무겁고 거칠었습니다.
반면 최근 방식은
공간을 더 연속적으로 표현하고,
이미지만으로도 더 자연스러운 3D 장면을 복원하려고 합니다.
그 흐름에서 대표적으로 등장한 것이 바로 NeRF 입니다.
다만 이 부분은 아직 입문 단계에서는
“최근 3D 연구는 단순 mesh 저장을 넘어서, 장면을 함수처럼 표현하는 방향으로 발전하고 있다” 정도만 이해하면 충분합니다.

7. 최종 정리
오늘 내용을 정말 짧게 요약하면 이렇습니다.
첫째, 디지털 트윈은 단순한 3D 그래픽이 아니라
현실 공간을 디지털 공간으로 옮기는 과정에서 출발합니다.
둘째, 3D 재구성은
2D RGB 이미지를 3D 표현으로 바꾸는 문제입니다.
셋째, 그 과정은 보통
이미지 수집, 깊이 추정, 카메라 위치 추정, 대응점 탐색, 3D 형태 복원, 텍스처 복원 순서로 이해할 수 있습니다.
넷째, 이렇게 복원된 3D는
voxel, point cloud, mesh, implicit representation 같은 여러 형식으로 저장될 수 있습니다.

8. 마무리
디지털 트윈을 공부하다 보면
처음부터 시뮬레이터, 로봇, 센서, AI 모델 같은 응용 주제로 바로 들어가고 싶어질 수 있습니다.
그런데 그 전에 반드시 먼저 이해해야 할 질문이 있습니다.
“현실 공간을 컴퓨터 안에 어떤 형태로 옮길 것인가?”
이 질문에 대한 가장 기초적인 답이
바로 오늘 본 3D 재구성입니다.
즉 디지털 트윈의 출발점은
화려한 3D 화면이 아니라,
2D 이미지에서 3D 공간 정보를 복원하는 과정이라고 볼 수 있습니다.
다음 글에서는 오늘 마지막에 잠깐 언급한
Voxel, Point Cloud, Mesh, Implicit Representation을 비교하면서,
각 방식이 왜 다르고 어디에 강한지 더 쉽게 풀어보겠습니다.